Staying Sharp with Leetcode
Project Completion: Ongoing
Project Description:
Leetcode is a website targeted at solving niche problems involving algorithms, data structures, multiple programming languages, the UNIX shell and more. Traditionally leetcode is site that new or upcoming graduates use to prepare for technical interviews when seeking a job, but it works just as well for anyone looking to stay sharp with the more theoretical computer science skills acquired at university (plus they support my two favorite languages, C/C++ and Python). Visit leetcode here.
Check out my solutions to some leetcode problems on GitHub.
Infinity Table v1.0
Project completion: August 2016
Project Description:
An infinity mirror is created by sandwiching some lights in between the reflective side of a one-way-mirror and the reflective side of a traditional mirror. The two mirrored surfaces reflect the light back and forth between one another creating the appearance of infinite depth. By using a one-way-mirror, some light is allowed to escape enabling a spectator to view the effect. Because some of the light is allowed to escape and some is also absorbed by the non-reflective surfaces between the sandwich, the effect does not persist into infinity. For this reason it is extremely important to use a very high quality one-way-mirror (as opposed to say, car tint on a piece of clear glass) as it will make the illusion depth appear to be much greater. It is also important to use the brightest LEDs you can find, because the one-way-mirror substantially cuts down on the amount of light allowed to escape, dimming the brightness of LEDs as if you were wearing sunglasses.
This project was a joint effort between my Dad and myself (and a few errant friends toward the end) as there was a lot that had to be done. The wood is actually from an old bookshelf that my Mom and Dad bought for my apartment during school. It was $10 and made from solid oak, so the lumber alone made that shelf a good investment. The shelf was stained and had to be completely resurfaced before we could cut it down, and stick it all back together as a coffee table. Everything uses pocket screw so that there are no exposed screw heads and the table has 6 layer of polyurethane coating the surface (4 regular fast dry poly and 2 spar to protect the wood from UV and moisture).
The LEDs are APA102 based and were purchased from Pololu electronics. These particular LEDs are the highest-density APA102s that I am aware of on the market at 144 LEDs per meter. However they are only sold in half-meter strips due to voltage drop across the strip (yes, they are super super bright), which means you have to put a bunch of strips together and then power each one individually to prevent the color from becoming increasingly red. At the moment, the LEDs are driven by an Arduino UNO via standard SPI, though I plan to swap that out for a Raspberry Pi any day now. The Pi will let me do really cool things like slice up images and use them as a bit stream of colors to the LEDs (if that makes no sense watch this video to get an idea of what I mean).
Check out a gallery of my infinity table with a bunch of photos and some videos of it in action. To entice you, check out this picture of the table set up in my living room:

Thesis Research - The Unreliable Assignment Problem
Project completion: May 2016
Project Description:
For my Masters degree at SMU, I published a thesis with research investigating how to reduce resource requirements for fault tolerance in highly distributed systems. In order to complete my research I had to run several billion simulations so I got to use the SMU super computer (Maneframe). It made my little 3 nodes Raspberry Pi cluster look like a joke. All simulations were written using Python and C with a touch of Cython as my go-between. All the heavy lifting is done in C and distributed to more than 40, 8-core worker nodes (although we had over 1,000 nodes in the cluster) and then reassembled and post processed with Python using numpy, scikit learn and a bunch of the Anacondas distribution.
The proposed methods in my research all revolve around taking advantage of increasingly common low latency links, like you get with fiber, to migrate virtual machines in the event of a large scale blackout or natural disaster (hell, I have 1Gbps link up and down in my house). We investigated how VMs should be provisioned in a pool of resources to see if this can yield any promising results with regards to ensuring that there is always a place for a failed machine to move its VMs. This was tested both on networks represented as a fully-connected graph and also on networks represented as a scale-free network (a Barabasi-Albert graph to be precise). In the end I got semi-promising results that suggest that there is some merit in pursuing future work in the space.
Checkout the code on GitHub or read the whole thesis on ProQuest.
Algorithm Engineering - Finding Communication Backbones in a Wireless Sensor Network
Project completion: December 2015
Project Description:
Nearing the end of my master's degree I had the pleasure of taking Algorithms Engineering with Dr. David Matula, who has done a significant amount of work in the graph theory space. For my end of semester project I created a program and corresponding visualization that was targeted at finding communication backbones in wireless sensor networks.
As it turns out random geometric graphs (RGG) are extremely good at modeling wireless sensor networks. This is because an RGG's edges are determined by a vertex's proximity to another vertex. These two vertices have an edge between them if they are less than some distance r from each other. In this case r is an analog to the broadcast radius of a wireless sensor. In a real world wireless sensor network, sensors may be dropped from a plane or scattered on the ground in some unpredictable fashion. It is useful to be able to create a communication backbone between these sensors so that you can extract data from all the sensors from only one (or very few) egress sensors. Imagine that it would be much nicer to walk to and download information from one sensor than to gather information individually from all sensors that are scattered throughout some arbitrarily large geographic area. Using "smallest last ordering" and graph coloring algorithms were able to reliably choose pretty good backbones, using a program and any random geometric graph as input. This project was extremely in depth so I recommend that you click here to explore the project further and read the whole project description as well as check out the cool visualizations I made to display the work that has been done.

Raspberry Pi Beowulf Cluster
Project completion: May 2013
Project Description:
I have always been amazed by highly distributed systems, an in particular super computers. Long before I had the opportunity to use ManeFrame at SMU (our on-campus high performance cluster) I wanted to try out the concepts of super computing for myself. I spoke with one of my professors and managed to borrow 3 Raspberry Pi Model Bs and decided to turn them into my own little mini-cluster. After researching substantially I managed to link all three nodes together with a custom made power supply, rack and a spare wireless switch I found laying around my house. Once the networking was complete these nodes could communicate over MPI (message passing interface) to perform distributed computation. This type of cluster is often referred to as a Beowulf cluster, as opposed to a Hadoop, Elasticsearch, etc. cluster. I was able to do some simple monte carlo simulations to demonstrate that it worked. Although this project was not incredibly substantial it really got me interested in cloud and distributed computation which would eventually lead me to my thesis work! I think it would be awesome to build a bigger version of the same thing using the much improved Raspberry Pi 3 which sports not 1 but 4 fours per node. They come in at around the same price point which makes building a 32 core machine comparatively inexpensive (8 boards x $35 = $280).

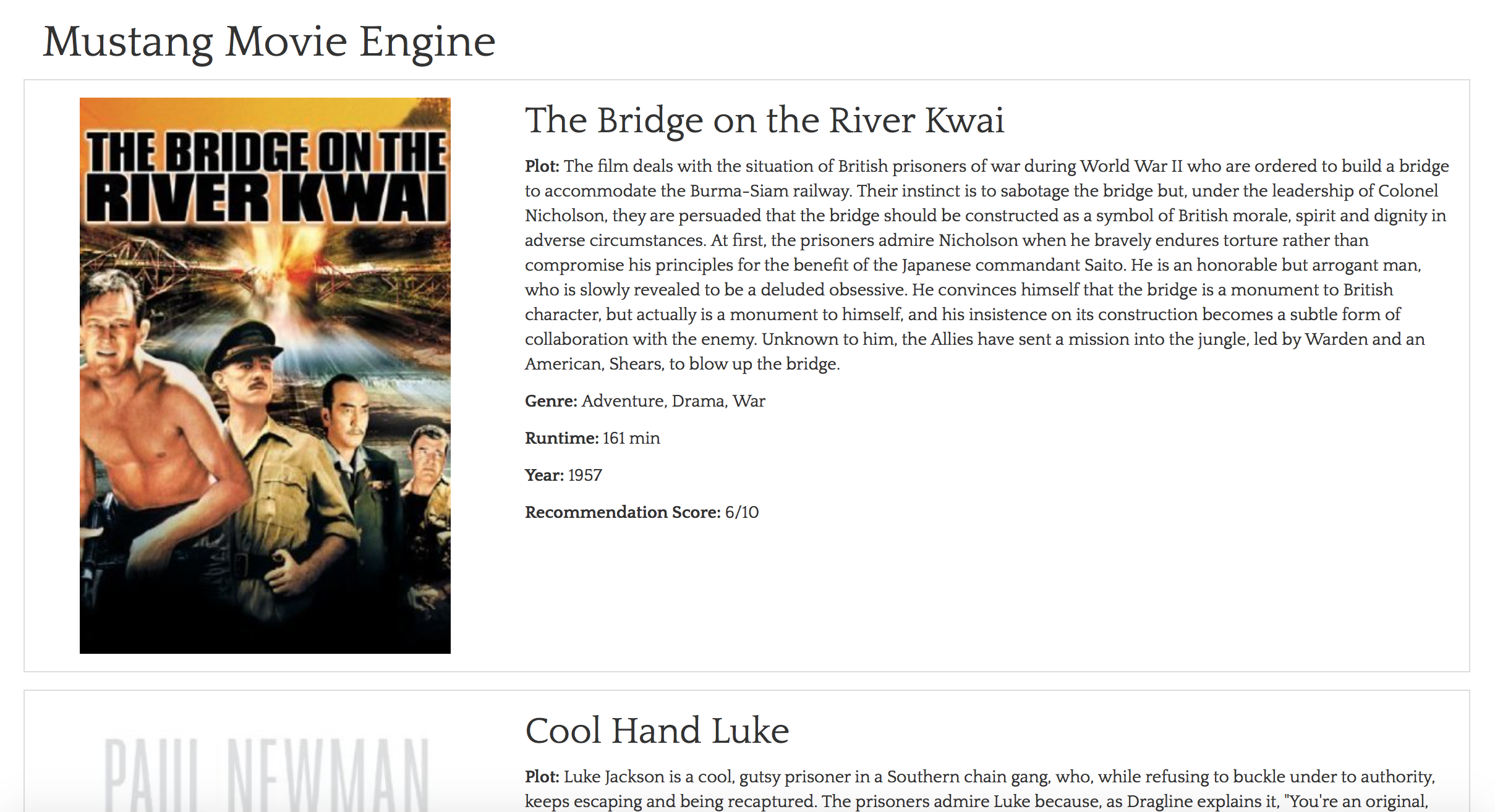
Movie Recommender based on Netflix Data
Project completion: May 2015
Project Description:
I built a machine learning, movie recommender with some classmates using the Dato (aka GraphLab, aka Turi) toolkit. We deployed this recommender service on an Amazon EC2 instance as a REST service with an Angular based front-end. This front-end makes asynchronous calls to the recommender service, the IMDB API to load content about the movies being recommended, as well as a separate IMDB service that loads images of movie posters. This allowed us to have a beautiful, well-formatted experience in a single dynamic webpage. I really enjoyed this project because we got to combine skills in machine learning, service based architecture and cloud infrastructure on both the front-end and back-end.
C++ Wikibooks Search Engine
Project completion: December 2012
Project Description:
Our final semester project for CSE 2341 - Data Structures, a notoriously difficult undergraduate class at SMU, was to build a fully functioning search engine in C++. This search engine was designed to ingest and index over 250,000 XML formatted books and articles dumped from wikibooks.org. An inverted file index was generated from the data along with relevancy scores for each word in the form of a TF/IDF score. We also implemented simple boolean queries so that the user could execute slightly more complex queries in the form of Seattle AND Boston or Coffee OR Tea.
One of the interesting things about this project is that the input database, plus index and meta-data could not fit in memory (at the time we only had either 2 or 4GB RAM). This forced us to create a minimized index that would reside in memory while the actual contents of the books were split up and stored on disk. When a query would return that article as a result, the program would fetch the article data from disk. This meant that we could afford to search over a tremendously large amount of data without affecting the user experience on the machine. As another plus, this minimized index could be read into memory in a matter of seconds compared to re-indexing all of the XML that would take many minutes to complete.
This was without a doubt one of the coolest projects I got to work on as an undergraduate because of the many many new things I learned about how a search engine and high performance program needs to operate.
Checkout the code on github.
![]()